2019/06/17 M zabbix监控项及核心功能模块全面讲解和演练
本文共 3644 字,大约阅读时间需要 12 分钟。
监控系统由4个功能,采样,存储,展示,报警 采样可以有4种通道来完成,lpml。agent,snmp,jmx 存储有:sql,rrd轮询数据,nosql 展示:web gui ,app 报警:发送通知需要用媒介来完成
 安装server端主要有,zabbix-server-mysql,zabbix-get webgui:zabbix-web,zabbix-web-mysql agent:zabbix-agent,zabbix-sender proxy zabbix代理服务器:zabbix——proxy
安装server端主要有,zabbix-server-mysql,zabbix-get webgui:zabbix-web,zabbix-web-mysql agent:zabbix-agent,zabbix-sender proxy zabbix代理服务器:zabbix——proxy  无论server还是agent端,日志和unitfile 都遵循固定法则来进行定义
无论server还是agent端,日志和unitfile 都遵循固定法则来进行定义 zabbix监控配置: host group–> host–>item 组=applications–>(在host上定义)item(定义图形)–>trigger触发器(产生event) action(condition,operaton一条件满足就进行操作)
 item key有两类, 一种是内建的 一种是自定义的(user parameter、 采集到的数据类型有哪些: 数值: 整数 浮点数 字符串: text log 采集到数据后该怎么存储 AS IS 不对数据做任何处理,存储采集到的数据本身 delta(simple change)本次采样的数据减去前一次采样的数据 delta(speed per second)本次采样的数据减去前一次采样的数据,再除以经过的时间长;速率数据;
item key有两类, 一种是内建的 一种是自定义的(user parameter、 采集到的数据类型有哪些: 数值: 整数 浮点数 字符串: text log 采集到数据后该怎么存储 AS IS 不对数据做任何处理,存储采集到的数据本身 delta(simple change)本次采样的数据减去前一次采样的数据 delta(speed per second)本次采样的数据减去前一次采样的数据,再除以经过的时间长;速率数据; 
 last最新的值,min最小值,avg平均值,max最大值 再去创建一个监控系(一个是内建的,一个是自定义的) 定义一个item
last最新的值,min最小值,avg平均值,max最大值 再去创建一个监控系(一个是内建的,一个是自定义的) 定义一个item 
 item也是有类型的
item也是有类型的 
 内建的里面 agent代表 被动模式 zabbix agent (active)主动模式下的 ssh的话要输入账号密码
内建的里面 agent代表 被动模式 zabbix agent (active)主动模式下的 ssh的话要输入账号密码  带<>的key代表能接收参数的key
带<>的key代表能接收参数的key  if后面第一个参数指定网络接口
if后面第一个参数指定网络接口  []中括号传递参数,eno16777736,第二个参数(packets报文单位,还是bytes字节单位)
[]中括号传递参数,eno16777736,第二个参数(packets报文单位,还是bytes字节单位) 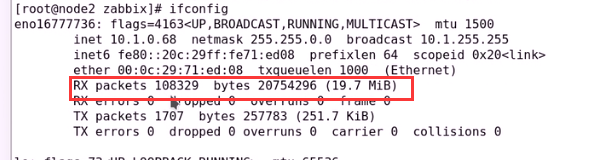
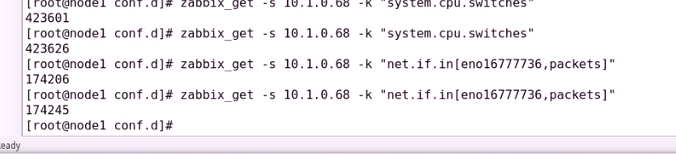 指明字节
指明字节  应该是下面的数据
应该是下面的数据  也可以使用out获取数据,只不过传送出去的
也可以使用out获取数据,只不过传送出去的 
 decimal十进制数据
decimal十进制数据  也可以不固定5秒钟,因为白厅可以密集点,晚上可以稀疏一点 每隔5秒,周一到周五,9点到18点 每隔30秒,周一到周日
也可以不固定5秒钟,因为白厅可以密集点,晚上可以稀疏一点 每隔5秒,周一到周五,9点到18点 每隔30秒,周一到周日 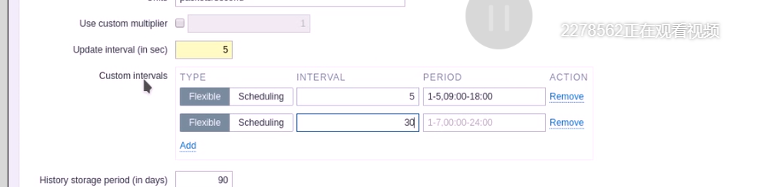 可以调度只再哪些时间进行监控
可以调度只再哪些时间进行监控  趋势数据保存365天
趋势数据保存365天  new application 名称
new application 名称  也可以用clone方式来添加
也可以用clone方式来添加  其他都跟之前一样
其他都跟之前一样  还可以继续复制 出站的报文数
还可以继续复制 出站的报文数  继续clone
继续clone  定义好后在latest data最新数据看
定义好后在latest data最新数据看  也可以定义一个主动监控的item
也可以定义一个主动监控的item 
 配置好item后,就需要配置trigger了 触发器就是来定义这个监控项上的数据的合理性
配置好item后,就需要配置trigger了 触发器就是来定义这个监控项上的数据的合理性  触发器就是来定义什么是合理区间的,但是触发的表达方式很独特,是一个表达式
触发器就是来定义什么是合理区间的,但是触发的表达方式很独特,是一个表达式  假如认定之前的报文每秒发送100是合理,大于100是不合理 符合条件是有问题的,不符合条件反而是合理的,这样做就是为了触发器产生的
假如认定之前的报文每秒发送100是合理,大于100是不合理 符合条件是有问题的,不符合条件反而是合理的,这样做就是为了触发器产生的  单独采样一次可能是一个偶然性的值,未必是真正出现故障的,所以problem应该多采样几次才认为是故障,第一次采样不合理的,再来一次不合理,就真的是不合理,从problem转换成ok,一次是ok,第二次还是ok,才认为是ok,可以慎重一点
单独采样一次可能是一个偶然性的值,未必是真正出现故障的,所以problem应该多采样几次才认为是故障,第一次采样不合理的,再来一次不合理,就真的是不合理,从problem转换成ok,一次是ok,第二次还是ok,才认为是ok,可以慎重一点  一个item可以定义不同表达式,定义不同的严重等级
一个item可以定义不同表达式,定义不同的严重等级  阈读yu值 触发器如何表示 每一个监控项都应该是主机上的监控 所以就需要指明哪个主机上的:<key哪个监控项,.function代表采样得到的数据评估是否在合理区间内使用的函数, 这个action就可以取平均值AVG,最大值max,nodata没采集到数,sum求和。
阈读yu值 触发器如何表示 每一个监控项都应该是主机上的监控 所以就需要指明哪个主机上的:<key哪个监控项,.function代表采样得到的数据评估是否在合理区间内使用的函数, 这个action就可以取平均值AVG,最大值max,nodata没采集到数,sum求和。  parameter,这个函数要对指定时间的采量求(比如以最大值为例,求最大值,或者指定次数范围内的来求最大值)
parameter,这个函数要对指定时间的采量求(比如以最大值为例,求最大值,或者指定次数范围内的来求最大值)  然后用operator,跟常数constatnt做比较
然后用operator,跟常数constatnt做比较  不同的zabbix版本可能不太一样 一般ok转为problem就表示触发一个事件了 从problem转为ok也可以称为recovery 事件,回滚,恢复
不同的zabbix版本可能不太一样 一般ok转为problem就表示触发一个事件了 从problem转为ok也可以称为recovery 事件,回滚,恢复  触发器表达式,server:item,对item而言采集到的数还要用function的参数parameter(最近几次的,最近多长时间内的)做评估,评估的结果用某个操作符operator 与常数constant作比较
触发器表达式,server:item,对item而言采集到的数还要用function的参数parameter(最近几次的,最近多长时间内的)做评估,评估的结果用某个操作符operator 与常数constant作比较 
 operator就是操作符
operator就是操作符 
 所有cpu all,avg1 一分钟内的 0表示最后采样 如果把刚才定义的某一个item,如果每秒钟平均入站字节数大于500就触发警报
所有cpu all,avg1 一分钟内的 0表示最后采样 如果把刚才定义的某一个item,如果每秒钟平均入站字节数大于500就触发警报 
 是有级别的,入站速率太高 表达式
是有级别的,入站速率太高 表达式 
 如果最后采样值大于100,就认为不合法
如果最后采样值大于100,就认为不合法  最近一次,会自动帮你生成#1
最近一次,会自动帮你生成#1 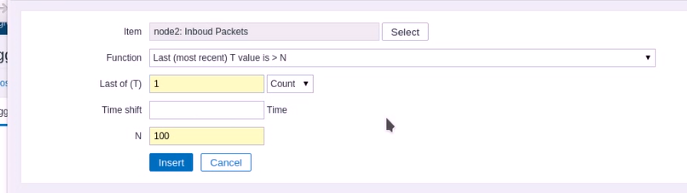 就自动帮你生成结果了
就自动帮你生成结果了  如果没有采取相关措施要不要多次去触发事件 定义触发器的依赖关系
如果没有采取相关措施要不要多次去触发事件 定义触发器的依赖关系 
 现在修改一下触发器规则100太大了
现在修改一下触发器规则100太大了 
 修改成15
修改成15 
超出这个线的就是超出阈值了
 现在做一次ping请求,或者下载报文 下载一个大包
现在做一次ping请求,或者下载报文 下载一个大包 
 两个机器事件不一致
两个机器事件不一致  、
、 触发了就看下event
触发了就看下event  events记录的是最近所产生的事件
events记录的是最近所产生的事件 
 可以显示哪个主机过去什么时间发生了什么
可以显示哪个主机过去什么时间发生了什么  这个一般默认是在最上面的,可以拖动
这个一般默认是在最上面的,可以拖动  根据所定义的所有的item,平局每秒钟大概插入几个数据 一般监控几百台这个 nvps是很大的
根据所定义的所有的item,平局每秒钟大概插入几个数据 一般监控几百台这个 nvps是很大的  有了trigger就能触发事件了,从每次ok到problem触发之后该怎么办,就需要定义action action由condition和operator来组成 一般选择触发器事件
有了trigger就能触发事件了,从每次ok到problem触发之后该怎么办,就需要定义action action由condition和operator来组成 一般选择触发器事件  这个action是什么 在什么条件下触发这个action, 一旦触发以后action,需要做什么
这个action是什么 在什么条件下触发这个action, 一旦触发以后action,需要做什么  A。非维护期间内 B。某个触发器的条件从ok到problem才发送警告
A。非维护期间内 B。某个触发器的条件从ok到problem才发送警告 
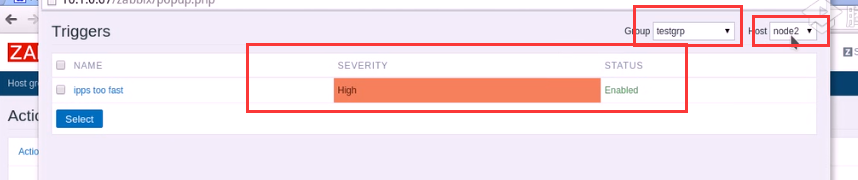 三个条件是同时满足还是或者,默认是A and B and C
三个条件是同时满足还是或者,默认是A and B and C  所以一个action需要基于某个触发器所产生的的事件来产生操作的 触发器之间还可以存在依赖关系 监控机和路由有链接,主机组在路由器后方,如果某一刻,发现路由故障了,还能采集到后方的数据吗(未采集到不一定就发生故障了,所以定义路由器上的触发器产生故障,那么其他主机能够被采集到数据是依赖于路由器可以和监控主机发生通讯,如果路由发生故障,主要路由报警就可以了,后面的主机采集不到数据就不需要报警了)这就是触发器之间的依赖关系
所以一个action需要基于某个触发器所产生的的事件来产生操作的 触发器之间还可以存在依赖关系 监控机和路由有链接,主机组在路由器后方,如果某一刻,发现路由故障了,还能采集到后方的数据吗(未采集到不一定就发生故障了,所以定义路由器上的触发器产生故障,那么其他主机能够被采集到数据是依赖于路由器可以和监控主机发生通讯,如果路由发生故障,主要路由报警就可以了,后面的主机采集不到数据就不需要报警了)这就是触发器之间的依赖关系  监控一台服务器,这台服务器都不在线了,就不需要去报其他应用故障,比如nginx,memacache
监控一台服务器,这台服务器都不在线了,就不需要去报其他应用故障,比如nginx,memacache  所以定义良好的依赖关系,一次报警就能定义各种问题,在后来定义触发器的时候一定要依赖关系 主机要依赖于网络设备,服务依赖于主机,监控的所有nginx指标都依赖于nginx服务
所以定义良好的依赖关系,一次报警就能定义各种问题,在后来定义触发器的时候一定要依赖关系 主机要依赖于网络设备,服务依赖于主机,监控的所有nginx指标都依赖于nginx服务  这就叫触发器间的依赖关系
这就叫触发器间的依赖关系  报警之前还可以先执行一个命令,点击new会生成第一步操作,可以发邮件,也可以执行远程命令
报警之前还可以先执行一个命令,点击new会生成第一步操作,可以发邮件,也可以执行远程命令  第一步,在5分钟之内先采取执行命令
第一步,在5分钟之内先采取执行命令  第二步,发警报
第二步,发警报  **从第2步到第三部,不断采样,还有故障,就发送,主机死了,这是报警的升级机制 action有两部分组成 condition 触发此动作的条件,一般通过事件触发, opertations 触发条件满足时要采取的动作, send message remote command 在agent所在的主机上运行用户指定的命令或脚本来尝试着恢复故障:例如 重启服务; 或者任何用户自定义脚本 **
**从第2步到第三部,不断采样,还有故障,就发送,主机死了,这是报警的升级机制 action有两部分组成 condition 触发此动作的条件,一般通过事件触发, opertations 触发条件满足时要采取的动作, send message remote command 在agent所在的主机上运行用户指定的命令或脚本来尝试着恢复故障:例如 重启服务; 或者任何用户自定义脚本 **  remote command类型有如下: IPMI命令 custom script (最为常用,能够在主机上执行的命令) ssh telnet global script
remote command类型有如下: IPMI命令 custom script (最为常用,能够在主机上执行的命令) ssh telnet global script  这种有两种运行放是,由agent或者server运行,一般都是agent运行,那么zabbix agent该用到什么身份来运行,可以用sudo 也可以用ssh方式
这种有两种运行放是,由agent或者server运行,一般都是agent运行,那么zabbix agent该用到什么身份来运行,可以用sudo 也可以用ssh方式  send message ,发消息给谁
send message ,发消息给谁 
 那么admin的收件地址是多少 以什么方式发送邮件就需要指明
那么admin的收件地址是多少 以什么方式发送邮件就需要指明  zabbix中的变量叫宏
zabbix中的变量叫宏  这就是发送信息的正文 sendmessage 功能就是发报警信息给关联的指定用户 发信息 信道有很多种,邮件只是一个统称,通过哪一个邮件服务器来发 可以通过脚本(调用短信机器人或者微信) 真要发邮件,需要定义media媒介
这就是发送信息的正文 sendmessage 功能就是发报警信息给关联的指定用户 发信息 信道有很多种,邮件只是一个统称,通过哪一个邮件服务器来发 可以通过脚本(调用短信机器人或者微信) 真要发邮件,需要定义media媒介 

 admin就可以定义以什么媒介来收取信息, 用什么地址收取邮件 什么时候能收取信息 可以定义哪些触发器触发的事件可以收邮件
admin就可以定义以什么媒介来收取信息, 用什么地址收取邮件 什么时候能收取信息 可以定义哪些触发器触发的事件可以收邮件  1.先定义媒介,2.定义相关用户,并且基于用户账号来关联某个邮箱上,3.才能定义send message 如果先用action就需要先定义media types、
1.先定义媒介,2.定义相关用户,并且基于用户账号来关联某个邮箱上,3.才能定义send message 如果先用action就需要先定义media types、 sms仅对北美的运营商有效 jabber北美的即时通讯软件 EZ texting 北美收费服务 所以可用就两种
sms仅对北美的运营商有效 jabber北美的即时通讯软件 EZ texting 北美收费服务 所以可用就两种  现在能用的邮件服务器仅是本地主机
现在能用的邮件服务器仅是本地主机 


 选择基于localmail,监控工程师什么都发,对于boss就等级搞点才发
选择基于localmail,监控工程师什么都发,对于boss就等级搞点才发  至此为止才能定义action
至此为止才能定义action  添加一个action
添加一个action 
转载地址:http://sbkgn.baihongyu.com/
你可能感兴趣的文章
C# WPF:把文件给我拖进来!!!
查看>>
生态和能力是国内自研操作系统发展的关键
查看>>
银河麒麟V10入选2020中国十大科技新闻
查看>>
Amazing 2020
查看>>
代码改变世界,也改变了我
查看>>
2021,未来可期
查看>>
阿星Plus:基于abp vNext开源一个博客网站
查看>>
写给自己,2020的年终总结
查看>>
Flash 生命终止,HTML5能否完美替代?
查看>>
ML.NET生成器带来了许多错误修复和增强功能以及新功能
查看>>
微信适配国产操作系统:原生支持 Linux
查看>>
我的2020年终总结:新的角色,新的开始
查看>>
C# 9 新特性 —— 增强的模式匹配
查看>>
ASP.NET Core Controller与IOC的羁绊
查看>>
如何实现 ASP.NET Core WebApi 的版本化
查看>>
探索 .Net Core 的 SourceLink
查看>>
AgileConfig-如何使用AgileConfig.Client读取配置
查看>>
【gRPC】 在.Net core中使用gRPC
查看>>
整合.NET WebAPI和 Vuejs——在.NET单体应用中使用 Vuejs 和 ElementUI
查看>>
“既然计划没有变化快,那制订计划还有个卵用啊!”
查看>>